








Building A1 DDP - Dubai Silicon Oasis
Industrial Area - 342001 -
Dubai - United Arab Emirates
+971 50 756 2346


SERVICES

COMPANY LINKS
SIGN-UP
For Newsletter





So here you are, staring at your screen, asking yourself What is machine learning? And why does it feel like everyone’s talking about it these days?
Maybe you’re curious how Netflix recommends shows, or how your phone unlocks with your face.
Behind it all are clever machine learning models, fueled by mountains of training data, learning to spot patterns using neural networks, learning algorithms, and sometimes wild techniques like reinforcement learning.
It’s no wonder the machine learning technology market alone is forecast to hit $503 billion by 2030 (1).
This guide breaks it all down. Supervised learning, unsupervised learning, deep learning, and how it all fits into the bigger world of artificial intelligence.
Let’s make sense of it together.
Machine learning (ML) is a subgroup of artificial intelligence that lets computer systems learn from data and improve at tasks without being explicitly programmed.
Instead of writing fixed rules for every situation, we feed training data to machine learning algorithms. As a result, they automatically identify patterns to predict or decide what to do when new situations arise.
Think of it like this:
A classic example is spam filtering.
Instead of programming an exhaustive list of spam keywords, we give the algorithm labeled training data (emails marked as “spam” or “not spam”).
The machine learning algorithms learn patterns that distinguish spam from legitimate emails. Once trained, the machine learning model can spot spam in new data it’s never seen before.
Other everyday uses of machine learning technology include:
And these examples barely scratch the surface.
By 2025, the world is projected to generate over 463 exabytes of data every single day (2), a scale impossible for humans to process manually. It’s no surprise that about 42% of enterprises already use AI and ML in business operations, with another 40% exploring it (3).
In essence, machine learning focuses on creating systems that perform complex tasks like recognizing faces, predicting prices, or even driving cars without being explicitly programmed for each scenario.
It’s what powers modern data science, generative AI services, and many innovative AI and machine learning projects.
Though the term feels like it just came around yesterday, machine learning has a rich backstory. Here’s a brief timeline:
Machine learning sits at the core of countless innovations, transforming industries from healthcare to finance, and powering everything from autonomous vehicles to robotic process automation.
Whether you’re exploring machine learning development services or simply curious, understanding this technology is key to making an impact in today’s data-driven world.
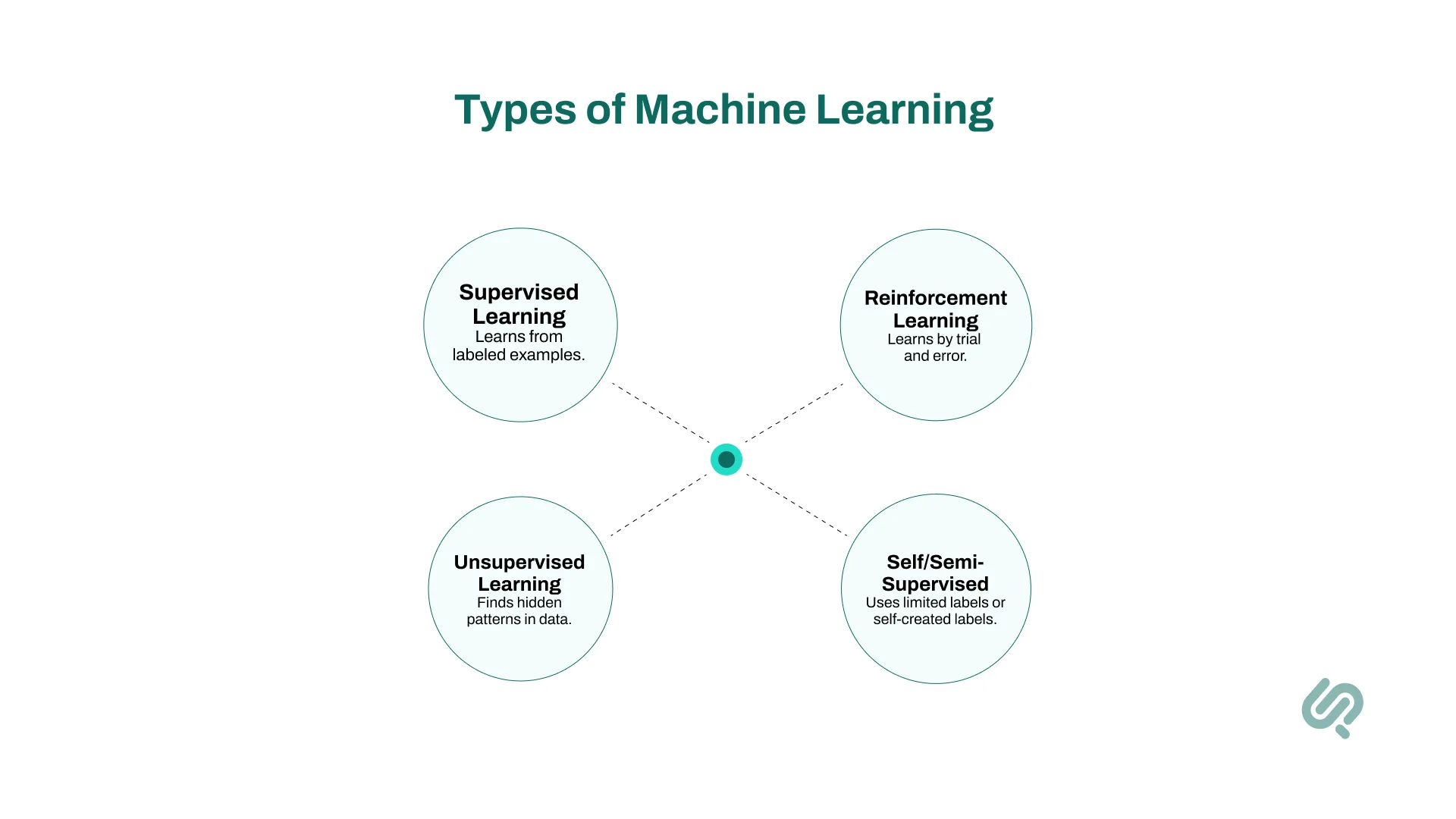
There’s no single way machines “learn.” Instead, machine learning technology encompasses several different approaches, each suited to different goals and types of training data.
Let’s break down the main types so you can see how these smart systems truly learn.
Imagine teaching a child with flashcards.
That’s the essence of supervised learning you show the algorithm examples (input data) along with the correct answer (labeled data).
Over time, the machine learning model learns to predict the right answer for new, unseen data.
For example:
Supervised machine learning uses many popular machine learning algorithms like linear regression, support vector machines, and neural networks. It’s the workhorse behind many machine learning applications because it’s powerful for solving specific tasks where historical examples are available.
Now imagine giving that same child a pile of puzzle pieces… but no picture on the box.
That’s unsupervised learning the algorithm explores data points without knowing the correct answers, seeking hidden patterns or groups.
It’s used for tasks like:
Methods include clustering algorithms like k-means, and techniques like Principal Component Analysis (PCA) (5). Unsupervised learning powers parts of data mining, helping businesses extract insights when they don’t know what patterns exist in advance.
Picture training a dog. Good behavior earns treats. Mistakes lead to time-outs.
That’s reinforcement learning (RL) in a nutshell. Algorithms learn by trial and error, maximizing rewards over time.
Unlike other methods, RL involves an agent (the algorithm) that:
Examples include:
RL shines in situations where decisions unfold over time and influence future outcomes. It’s one of the upcoming AI and machine learning trends and is pushing the boundaries of what machines can achieve.
Beyond these three pillars, there are hybrid techniques:
Machine learning companies and researchers continue to explore and combine these approaches to tackle increasingly complex tasks, such as building smart chatbots to enable self driving cars.
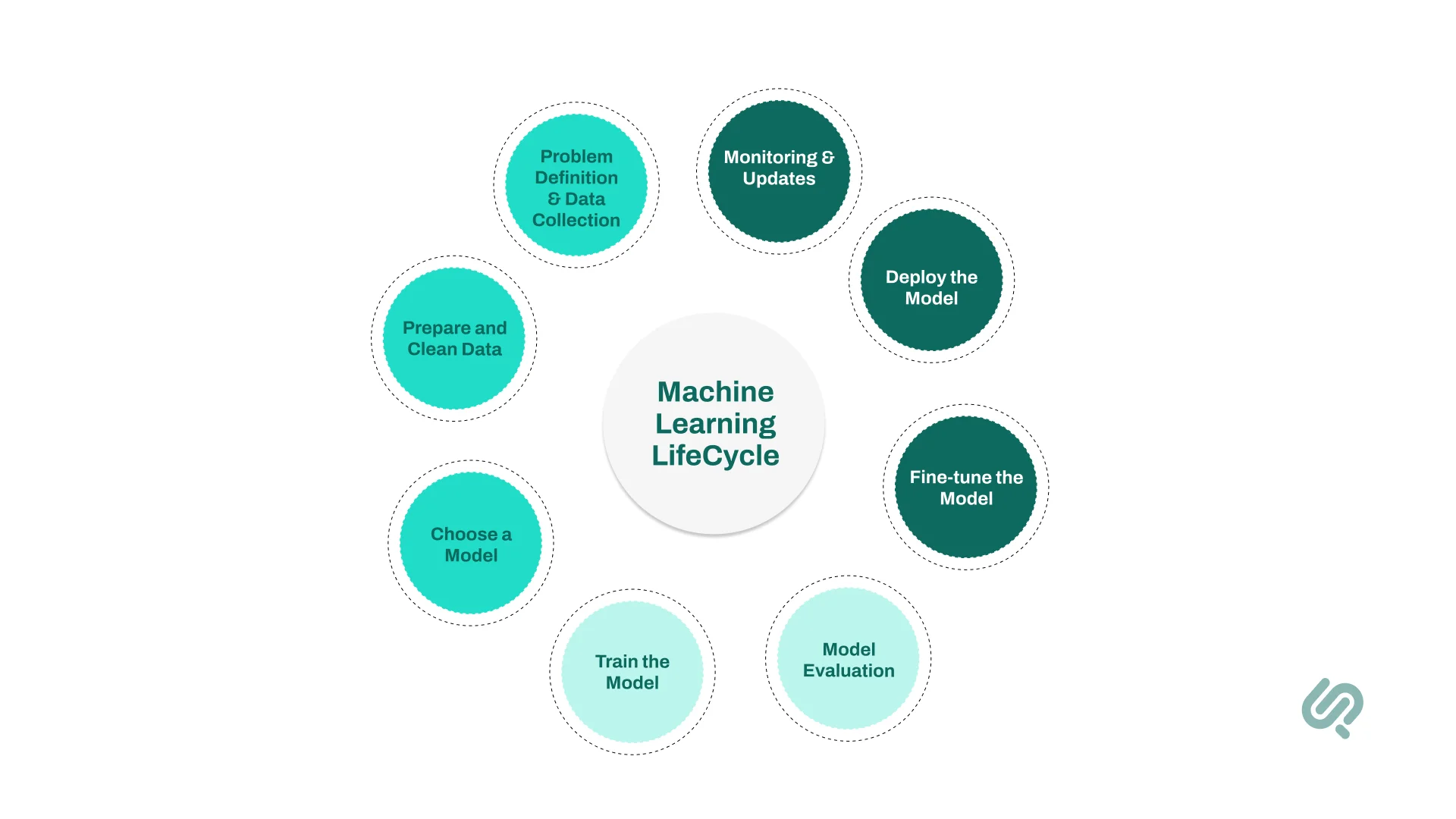
Machine learning (ML) is ultimately a loop of learning, testing, deploying, and improving. These steps can be visualized as the machine learning lifecycle, often summarized as:
Problem Definition → Data Collection → Data Preparation → Model Training → Model Evaluation → Deployment → Monitoring
The first step is to collect data. At the heart of every machine learning system lies data. Without enough training data, even the smartest machine learning algorithms can’t learn meaningful patterns.
A machine learning company might gather thousands of medical records for a healthcare machine learning project. Each with details like age, symptoms, and diagnosis, to train a model that predicts disease risk.
Secondly, this data has to be prepared and cleaned.
Raw data is messy. Data scientists perform data analysis and cleaning to fix errors, remove duplicates, handle missing values, and turn text or categories into numeric formats usable by machine learning models.
In a spam detection project, emails must be converted into numerical features (like word counts) so algorithms like support vector machines or deep learning models can process them.
The next step is picking the right machine learning algorithm or technique, based on your goal and data type.
Different problems call for different tools, so choose wisely.
Predicting house prices might use linear regression, while recognizing faces in photos leans on deep neural networks in computer vision applications. This choice is a big part of custom AI model development.
Next, it’s time to train the model. This is where learning happens.
The algorithm analyzes labeled training data to adjust its internal rules, aiming to identify patterns that predict correct outcomes.
A machine learning model learning to detect credit card fraud tweaks itself each time it guesses wrong until it can spot suspicious transactions reliably. Many models use a method called gradient descent to minimize errors during this training process.
Next, we test the model on new data it hasn’t seen to check how well it generalizes.
We measure performance using metrics like accuracy, precision, recall, or error rates.
An email spam filter might achieve 95% accuracy in tests. But if it misses too many spam emails or wrongly flags important messages, it needs improvement.
If the model isn’t good enough, data scientists tweak its settings (hyperparameters), try different learning algorithms, or add more data until performance improves.
A machine learning service provider might experiment with adding new features or increasing the layers in a deep learning architecture to boost results in a natural language processing project.
Once it performs well, the model is deployed into the real world, integrated into apps or business systems to make predictions on new data automatically.
Netflix uses deployed models to recommend shows tailored to each user’s tastes.
The journey isn’t over after deployment. Models must be monitored for changes in data trends (called data drift) and updated regularly to stay accurate.
A model predicting car prices might underperform if market conditions shift drastically, prompting a new round of machine learning projects to retrain it with fresh historical data.
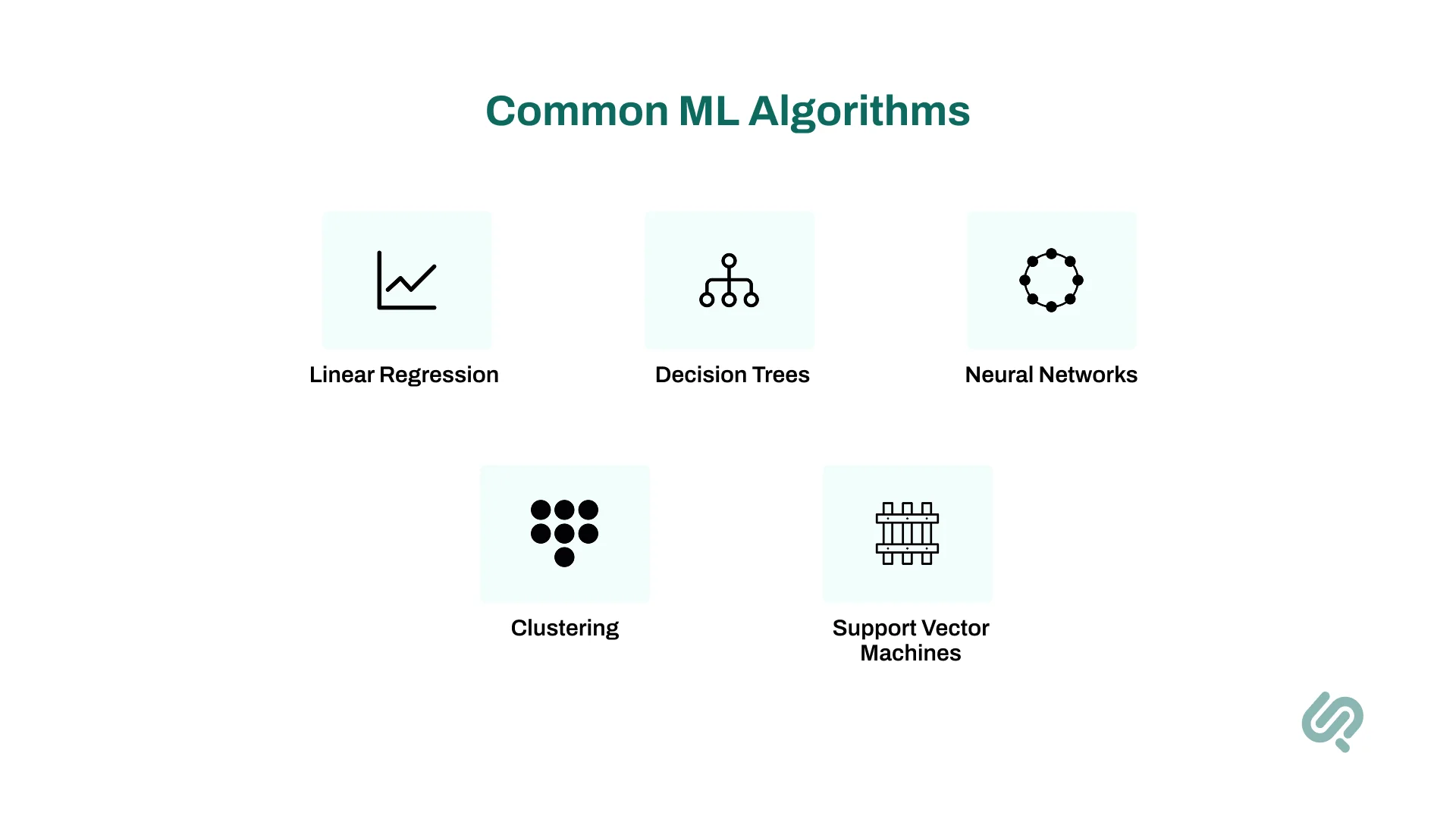
Different algorithms have different strengths.
Whether you’re exploring machine learning services or simply curious about how systems like natural language processing or computer vision work, these are the essential techniques that bring machine learning to life.
Let’s explore them one by one.
Linear regression is one of the simplest (and most powerful) algorithms in machine learning ML. It predicts a continuous number based on input data, assuming a linear relationship between inputs and outputs.
Imagine drawing the best-fit straight line through a scatterplot of data points. The slope and intercept of this line are calculated to minimize the difference between predicted and actual values a process called minimizing the “loss function.”
Predicting house prices based on size, location, and number of bedrooms. Even in today’s world of deep learning, linear regression remains a popular tool for fast, interpretable results, often used as a baseline in data science and machine learning projects.
Despite its name, logistic regression is used for classification, not regression. It estimates probabilities and assigns inputs to classes.
It takes the same linear equation as linear regression but squashes the output between 0 and 1 using a mathematical function called the sigmoid curve.
Predicting whether an email is spam or not. A model might say there’s a 92% chance an email is spam. It’s fast, interpretable, and widely used in areas like fraud detection or predicting disease presence.
A decision tree splits data into branches based on feature values, like a flowchart. Each internal node tests a feature, and leaves represent outcomes.
The algorithm picks the feature that best splits the data at each step, reducing impurity (e.g., using metrics like Gini impurity or entropy).
A tree might decide loan approvals based on income > $50,000, then credit score, etc. They’re easy to visualize and understand, making them popular in machine learning services where model transparency is essential.
A random forest grows many decision trees and combines their predictions for better accuracy. It’s an “ensemble method.”
Each tree is trained on a random subset of the data and features. By averaging predictions (regression) or taking a majority vote (classification), random forests reduce overfitting and improve generalization.
Predicting customer churn in telecom. Individual trees might differ, but the forest’s combined vote is usually reliable. Random forests often rank among top performers in machine learning competitions.
SVMs are powerful classifiers that separate data into classes by finding the optimal boundary (hyperplane).
SVMs maximize the margin the distance between the boundary and the closest data points (support vectors). They can also handle nonlinear separation using “kernels,” which project data into higher dimensions.
Classifying handwritten digits in images. Before deep learning became dominant in vision, SVMs were state-of-the-art in many tasks like speech recognition and text classification.
k-NN is simple yet surprisingly effective. It classifies data based on the “majority vote” of its nearest neighbors.
To classify a new data point, the algorithm finds the k closest points in the training data and assigns the most common label.
Classifying a fruit as an apple or pear based on size and color. Although computationally heavy for large datasets, k-NN is a favorite for quick, interpretable models in exploratory data analysis.
Naive Bayes uses probability and the assumption that all features are independent given the class hence “naive.”
It calculates how likely a data point belongs to a class based on individual feature probabilities.
Spam filtering in email. Even though word occurrences aren’t truly independent, Naive Bayes often works remarkably well for natural language processing tasks because of its speed and simplicity.
When there’s no labeled data, unsupervised learning steps in. Clustering algorithms like k-means group data into clusters based on similarity.
K-means starts by guessing cluster centers and moves them iteratively until data points are grouped optimally.
Segmenting customers into groups like “bargain hunters” vs. “premium shoppers.” Clustering fuels data analytics & AI insights for businesses looking to discover hidden patterns in data.
Modern deep learning models are inspired by how the human brain processes information. They consist of artificial neural networks with layers of interconnected nodes (neurons).
Each neuron transforms its input through a mathematical function and passes it forward. Deep architectures can capture extremely complex patterns by stacking many layers.
1. Convolutional Neural Networks (CNNs): Used in computer vision tasks like facial recognition in autonomous vehicles.
2. Recurrent Neural Networks (RNNs): Handle sequences like language or time series data.
3. Transformers: Power modern language models like GPT, handling text understanding and generation.
Each algorithm has trade-offs.
The choice depends on data size, interpretability needs, and the specific problem at hand.
Many people wonder about the difference between machine learning, traditional programming, and artificial intelligence.
These terms are often used interchangeably, but they represent different approaches in computer science and machine learning technology.
Let’s quickly define them in plain terms:
Here’s a snapshot of how they compare:
Traditional programming is like writing a recipe. A developer codes explicit instructions that a computer must follow. Every possible scenario must be anticipated and defined in advance.
How it works:
Example of Traditional Programming:
A tax calculator uses fixed formulas programmed into its logic. If a new tax rule appears that the program doesn’t know, it can’t handle it without new code.
While powerful for well-defined problems, traditional programming can’t adapt to new data or learn hidden patterns on its own. This rigidity is what machine learning seeks to overcome.
Unlike traditional programming, machine learning lets computers learn rules automatically from training data. Instead of explicitly coding every instruction, we feed examples to an algorithm and let it identify patterns and relationships.
How it works:
Example of Machine Learning:
Instead of listing spam keywords, a spam filter machine learning model learns patterns distinguishing spam from safe emails by analyzing thousands of labeled messages.
One Reddit user summed it up beautifully:
“Machine learning is the way a system uses algorithms to predict a value by learning patterns in data like voice search on your phone.”
Artificial intelligence (AI) is the broadest concept, the idea of machines demonstrating human-like abilities such as reasoning, learning, and perception. Machine learning is just one technique under this vast umbrella.
How it works:
Example of Artificial Intelligence:
Early AI programs played chess using hard-coded strategies. Modern AI like ChatGPT uses deep neural networks trained on enormous text data to generate human-like responses.
Not all AI is machine learning.
For instance, a rules-based chatbot that follows predefined conversation flows isn’t learning. It’s simply following scripted paths.
But machine learning applications have become the primary way modern AI systems achieve intelligence, enabling capabilities like speech recognition, robotic process automation, and computer vision.
Ultimately, the relationship looks like this:
AI ⊃ Machine Learning ⊃ Deep Learning ⊃ Neural Networks
In other words:
This distinction matters because it defines how flexible, adaptive, and intelligent a system can become.
In practice, modern AI solutions heavily rely on machine learning technology and machine learning algorithms work because they can tackle complex tasks with minimal human intervention.
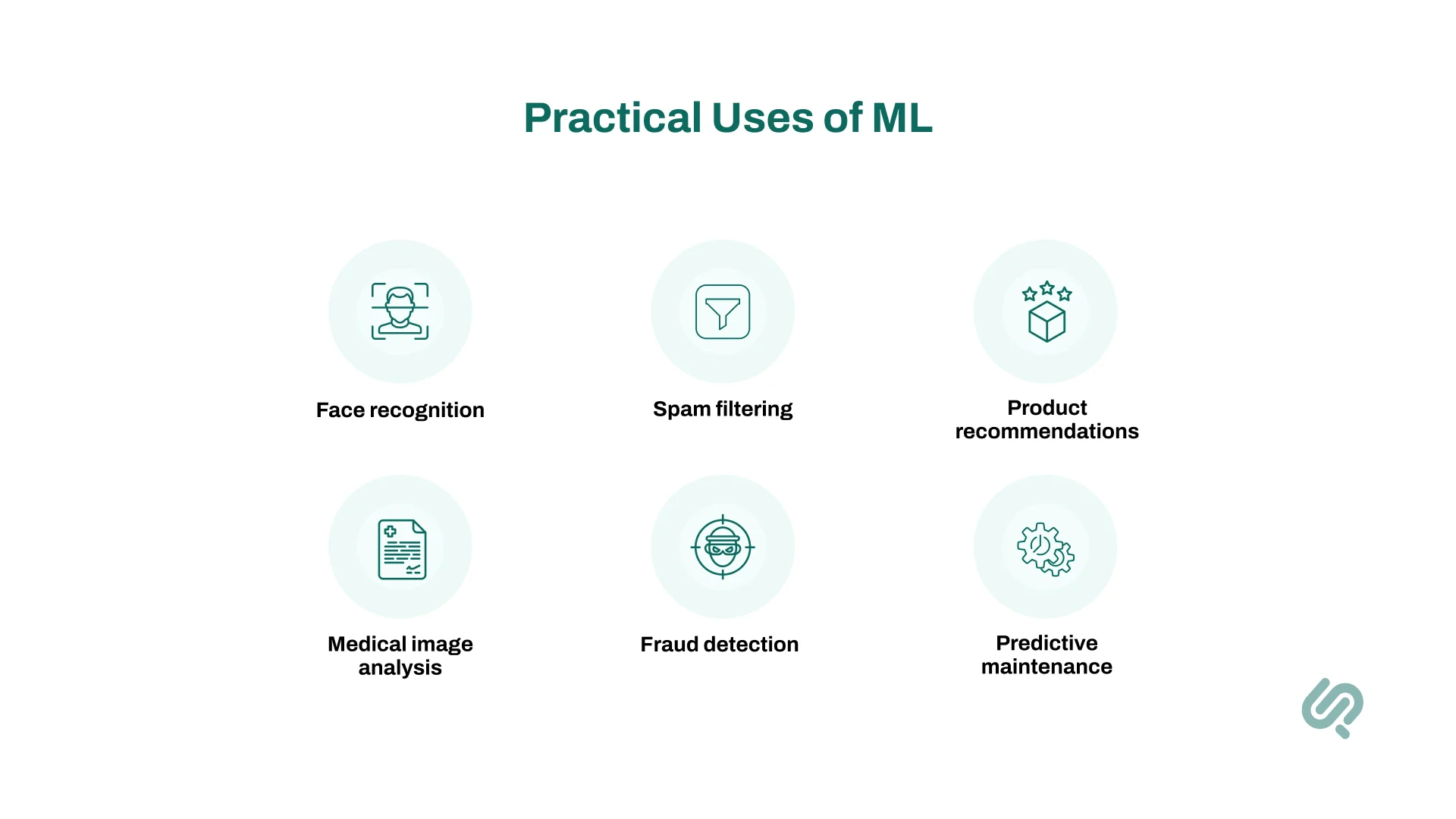
It’s one thing to ask what machine learning is. It’s another to see it in action!
Today, machine learning applications touch almost every part of our lives, transforming industries with systems that analyze data and perform tasks once thought impossible.
Let’s explore where machine learning is making the biggest impact.
Machine learning powers machines to “see” and understand images and videos, a field known as computer vision.
🔎 Case Study:
PhaedraSolutions developed an AI Cloud Surveillance Platform that uses deep learning to analyze video feeds and detect suspicious activity in real-time, dramatically improving security responses.
Machines now read, write, and understand human language thanks to machine learning programs in NLP.
Personalization drives engagement and revenue.
Amazon credits a large portion of its sales to its ML-powered recommendation engine (6), showing the business value of predictive analytics and pattern discovery.
In finance, ML protects customers and maximizes profits.
ML models in banking help reduce fraud losses, estimated in the billions annually.
Machine learning is revolutionizing patient care and drug discovery.
Businesses rely on ML for smarter customer engagement.
In manufacturing, ML boosts efficiency and reduces downtime.
🔎 Case Study:
Phaedra Solutions developed an AI Inventory Management System that helps businesses maintain optimal stock levels by predicting inventory needs from patterns in sales data and analyze data for real-time decision-making. The system is powered by high-quality data sets used in ai, allowing for improved forecasting and smarter real-time decisions.
ML goes beyond basic automation to tackle complex tasks.
Companies increasingly invest in AI workflow automation, seeking smarter, adaptable systems rather than rigid rules.

Organizations everywhere are investing in machine learning because it offers advantages that traditional systems simply can’t match.

While machine learning offers incredible advantages, it also comes with real-world challenges that every business and machine learning researcher should understand.
Successfully adopting machine learning requires thoughtful planning, technical discipline, and ethical responsibility.
Machine learning is transforming industries, helping us solve complex problems and uncover insights hidden in data.
It’s the reason apps feel smarter, businesses make faster decisions, and technology adapts to our needs in real time.
While its benefits are enormous, success depends on the right approach, quality data, and thoughtful implementation. Understanding both the possibilities and the limitations is the key to using ML effectively.
If you’re wondering how machine learning can add value to your business, we’re here to help you explore the possibilities.


Musa is a senior technical content writer with 7+ years of experience turning technical topics into clear, high-performing content.
His articles have helped companies boost website traffic by 3x and increase conversion rates through well-structured, SEO-friendly guides. He specializes in making complex ideas easy to understand and act on.
