








Building A1 DDP - Dubai Silicon Oasis
Industrial Area - 342001 -
Dubai - United Arab Emirates
+971 50 756 2346


SERVICES

COMPANY LINKS
SIGN-UP
For Newsletter





If you're reading this, you've probably come across the error "Please unblock challenges.cloudflare.com to proceed."
You searched for this Cloudflare outage guide because a critical part of the internet (whether it was X, ChatGPT, or Spotify) recently broke.
As of now, the Cloudflare outage on November 18, 2025 is fully resolved, but it exposed just how fragile the modern web truly is.
A single internal configuration error inside Cloudflare was enough to trigger hours of global failures across major apps, websites, APIs, and entire business systems.
This guide explains what happened, why it happened, and what website owners must do to stay online when Cloudflare goes down again.

The major disruption lasted for roughly three hours, from about 11:30 to 14:30 UTC on 18 November 2025, with all Cloudflare systems fully back to normal by around 17:06 UTC.
It temporarily broke or degraded access to a huge range of websites and apps behind Cloudflare, including X, ChatGPT, Spotify, Canva, Uber, NJ Transit and many more services that rely on its CDN and security layer.
A database-permissions change accidentally doubled the size of a configuration file used by Cloudflare’s bot-management system, triggering a latent bug that crashed core traffic-routing software across the network, a software/configuration failure, not a cyberattack.
Yes. Cloudflare says core traffic was largely restored by 14:30 UTC and all services were back to normal by 17:06 UTC on 18 November 2025, with the incident now marked as resolved.

On 18 November 2025, Cloudflare experienced a major global failure that made thousands of websites and apps briefly unreachable. (1)
The issue began around 11:20 UTC, when Cloudflare’s network suddenly stopped handling core traffic correctly.
Within minutes, users trying to access services such as X, ChatGPT, Spotify, Canva, and Uber started seeing widespread 5xx errors and the now-famous message: “Please unblock challenges.cloudflare.com to proceed.”
Although it looked like a massive cyberattack, Cloudflare later confirmed the outage was caused by an internal configuration issue, not hackers. (2)
A routine database-permissions update accidentally caused Cloudflare’s bot-management system to generate a feature file that was twice its normal size.
That oversized file exceeded a strict limit inside Cloudflare’s core proxy software (the component responsible for routing and filtering traffic). Once the proxy crashed, it triggered a chain reaction across Cloudflare’s global network, breaking traffic flow for millions of users.
Here are the key facts in simple terms:
Because so many platforms rely on Cloudflare for DNS, caching, routing, and security, even unrelated services went dark simultaneously.
Some outage trackers and news sites also failed to load because they themselves used Cloudflare’s infrastructure.
Cloudflare has now resolved the incident and is deploying preventative fixes so a single misbehaving configuration file can’t trigger an internet-wide failure again.
A Cloudflare outage happens when the problem is not with the website itself, but with the service sitting in front of it.
Cloudflare acts like a powerful security guard and traffic manager for almost half the internet. Think of it as the internet's "immune system." When this system fails, it affects millions of users instantly.
Cloudflare is a crucial middleman that makes the web faster and safer. It does 3 main jobs:
When Cloudflare breaks, you see specific, tell-tale errors. These are the signs that the issue is with the central provider, not the individual website.
It is a common mistake to think these outages are caused by outside hacking attacks. Cloudflare's own reports show that the true enemy is usually internal error. Small mistakes in software or settings quickly turn into global disasters, usually because underlying processes haven’t gone through proper digital transformation in business process management.
The November 18, 2025 outage fits the same pattern as most past failures: not a cyberattack, but an internal software and configuration issue that spread globally.
In this case, a bot-management configuration file exceeded a size limit and caused Cloudflare’s core proxy to crash
Cloudflare’s massive global network is designed to instantly spread changes everywhere. This speed is great for performance, but it means a bad change goes live across the entire internet instantly.
Sometimes, a security setting meant to protect websites does the exact opposite.
Outages can even start from seemingly harmless code changes made to the administration tools.
Even the oldest parts of the Cloudflare network can create new failures if they are not maintained perfectly.
The sheer size of Cloudflare’s network means that problems spread quickly and cause a chain reaction.

When Cloudflare goes down, the effects are immediate and far-reaching.
Because the company sits in front of such a large part of the internet (5), a single failure can disrupt multiple industries at the same time — from social apps and AI tools to e-commerce platforms and critical infrastructure.
The November 18 outage showed how deeply Cloudflare is woven into the modern web. Entire categories of services slowed down or went offline within minutes.
In some cases, even outage-tracking websites like DownDetector struggled to load because they also depended on Cloudflare’s network.
Below are the types of systems that typically experience problems during a widespread Cloudflare outage:
Across all of these categories, the pattern is the same: even when the services themselves are healthy, their ability to serve users collapses because the Cloudflare layer responsible for routing, protecting, and accelerating traffic has failed.
A Cloudflare outage sends shockwaves through financial markets, digital economies, and even public infrastructure. When a company responsible for such a large portion of global internet traffic fails, the impact reaches far beyond slow-loading sites.
Some of the most significant consequences include:
Cloudflare’s own share price often drops sharply during major outages (6), reflecting investor concerns about reliability and the risk of repeated failures. A single widespread outage can wipe out millions in market value within hours.
Cryptocurrency exchanges like Coinbase rely heavily on Cloudflare for security and traffic management. When they go offline, trading halts, price data becomes unreliable, and volatility increases, proving that even “decentralized” markets depend on centralized infrastructure.
When financial data providers, transit systems, and public-facing government services become unreachable, the outage becomes a national-level risk. A single configuration error can momentarily disrupt systems that citizens and governments rely on every day.
Cloudflare’s position at the heart of the internet means its failures aren’t isolated technical issues — they’re systemic events with economic and operational consequences felt across entire industries.
Cloudflare's history shows a clear pattern. Major outages are almost always caused by internal problems, not outside attacks.
Usually, a small mistake in a setting or new code quickly spreads across their global network, causing widespread chaos.
Cloudflare is very transparent about its failures, which is helpful. Incidents like this show how critical software quality assurance is not just for features, but for the infrastructure that keeps entire industries online.
The table below shows the key times their internal mistakes caused the internet to break:
If your business loses money, users, or trust every time your website goes down, relying on a single provider like Cloudflare is a dangerous single point of failure.
True resilience means having a fallback plan, not just hoping Cloudflare never breaks again.
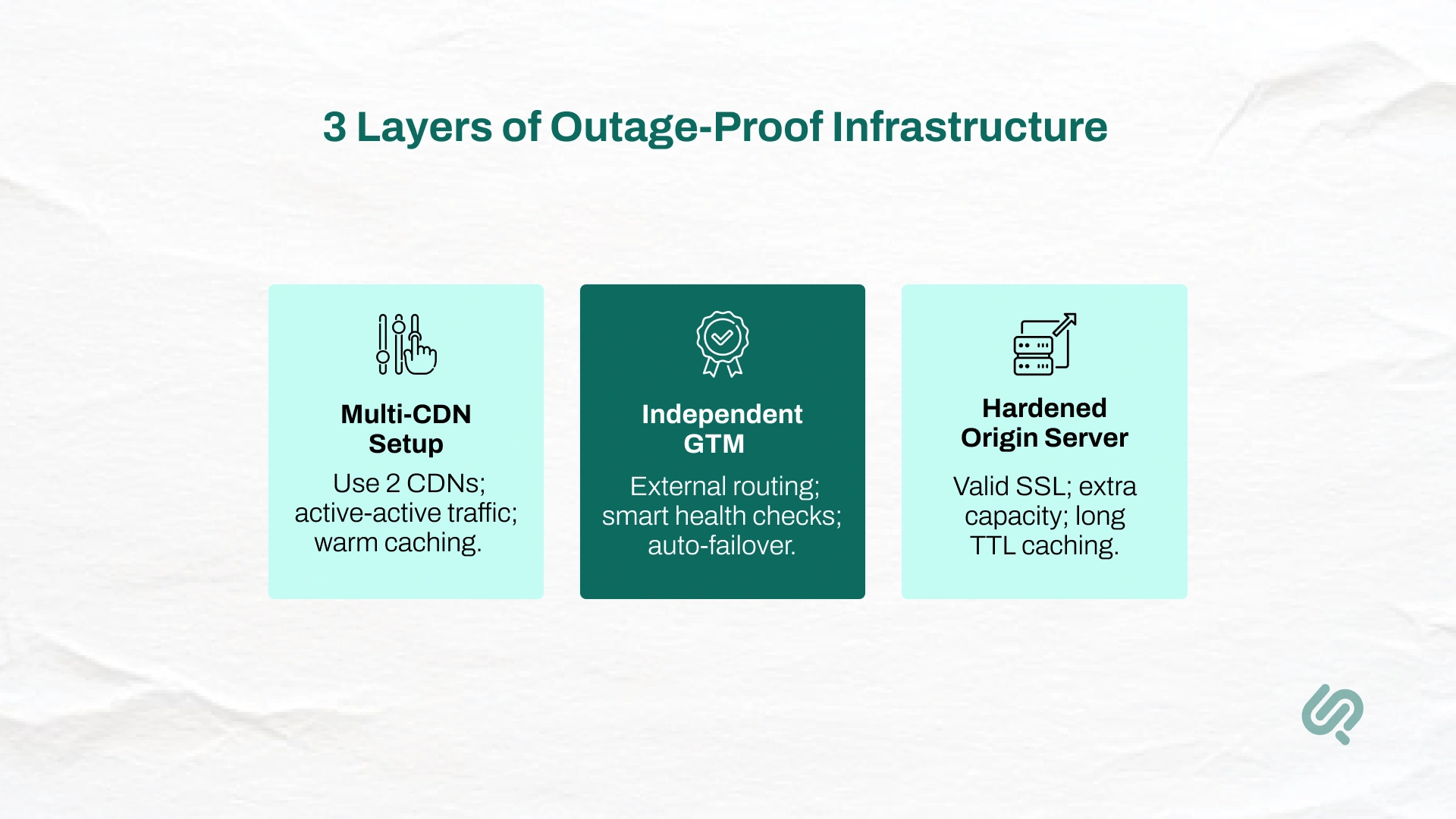
The most reliable approach is to design your infrastructure so that even if Cloudflare fails, your site doesn’t. That requires multiple layers of protection, redundancy, and smart automation.
Many teams now use generative AI for software development to automate tests, surface risky configs faster, and cut down the time from incident to fix.
Here’s how to build that safety net.
A Multi-CDN setup is the strongest way to keep your website online during outages. Instead of depending on one provider, you use two CDNs at the same time — so if one collapses, the other continues serving traffic.
Key steps:
A Multi-CDN setup only works if something automatically decides which CDN should serve users during an outage. That’s the job of GTM — an external traffic-routing system that operates outside Cloudflare.
What you need to do:
During the November outage, sites with GTM barely blinked — traffic shifted away from Cloudflare to the healthy CDN within seconds.
Even with multiple CDNs, your origin server must be ready to stand on its own if all other layers fail. If it can’t handle direct traffic, your fallbacks won’t matter.
Make sure you:
When Cloudflare goes down, website administrators need a steady, predictable plan. The goal is to keep users informed, avoid making the situation worse, and restore access wherever possible.

Start by confirming the issue is coming from Cloudflare and not your own systems. Check the official status page at cloudflarestatus.com and share it internally and publicly.
A short update on an independent channel (a non-Cloudflare-powered status page or your social media) reassures users that your servers are healthy and the disruption is upstream.
Once communication is handled, focus on technical stabilization.
Pause all deployments (both manual and automated) so you don’t introduce new variables during an outage.
If Cloudflare’s proxy is failing, you can temporarily route traffic around it by switching your DNS records from the “Orange Cloud” (Proxied) to the “Grey Cloud” (DNS Only), which sends visitors directly to your origin server. (7)
A few important safeguards:
To keep your response fast and structured, follow this simple checklist:
This approach helps your team stay calm, coordinated, and effective (even when the infrastructure beneath you isn’t).
The November Cloudflare outage made one thing obvious: the modern internet is built on a few critical pillars, and when one of them shakes, everything on top of it feels the impact.
It wasn’t a cyberattack. It wasn’t a global threat. It was a small internal mistake that managed to break huge parts of the web for hours.
That’s the reality businesses need to plan for.
Staying online isn’t about trusting one provider. It’s about building resilience: multiple CDNs, independent traffic routing, hardened origin servers, and systems that keep running even when one piece fails.
As AI and machine learning trends continue to shape monitoring, prediction, and self-healing systems, the goal is simple: outages that resolve themselves before most users even notice.
Companies that prepare for these disruptions barely notice them. Those that don’t often lose traffic, revenue, and customer trust in minutes.
The takeaway is simple: Cloudflare is powerful, but it should never be your only line of defense.

1. Cloudflare outage causes error messages across the internet — The Guardian
2. Cloudflare Apologizes After Outage Takes Major Websites Offline — Tom’s Hardware
3. UAE residents face delays; events disrupted in Cloudflare outage — Khaleej Times
4. Web Application Firewall — Wikipedia
5. Number of Websites Using Cloudflare Revealed Amid Global Outages — iHeart / Bobby Bones
6. Cloudflare Outage Disrupts X, ChatGPT and Others — Wall Street Journal
7. Using Cloudflare for DNS Hosting Only — CNewComer

Musa is a senior technical content writer with 7+ years of experience turning technical topics into clear, high-performing content.
His articles have helped companies boost website traffic by 3x and increase conversion rates through well-structured, SEO-friendly guides. He specializes in making complex ideas easy to understand and act on.
